
As large language models (LLMs) shift from static, training-bound knowledge recall to dynamic, inference-time reasoning, their supporting infrastructure must also evolve. Inference workloads are no longer just about throughput—they demand adaptive computation, modular scaling, and intelligent caching to deliver complex reasoning with real-world efficiency.
llm-d is a Kubernetes-native distributed inference stack purpose-built for this new wave of LLM applications. Designed by contributors to Kubernetes and vLLM, llm-d offers a production-grade path for teams deploying large models at scale. Whether you’re a platform engineer or a DevOps practitioner, llm-d brings increased performance per dollar across a wide range of accelerators and model families.
But this isn’t just another inference-serving solution. llm-d is designed for the future of AI inference—optimizing for long-running, multi-step prompts, retrieval-augmented generation, and agentic workflows. It integrates cutting-edge techniques like KV cache aware routing, disaggregated prefill/decode, and a vLLM-optimized inference scheduler, with Inference Gateway (IGW) for seamless Kubernetes-native operations.
Why llm-d is needed for efficient inference
The key innovation with llm-d is its use case: distributed model serving. Unlike traditional applications, LLM inference requests are vastly different from typical HTTP requests, and traditional Kubernetes load balancing and scaling mechanisms can be ineffective.
For example, LLM inference requests are stateful, expensive, and have varying shapes (in the difference of input tokens and output tokens). To build a cost-efficient AI platform, it’s critical that our infrastructure is used effectively, so let’s see what typically happens during inference.
Let’s say a user prompts an LLM with a question, such as customers who are up for renewal that we should reach out to. First, this request initiates a phase known as prefill, which computes hidden states (also referred to as the KV cache) for the input tokens in parallel. This is compute-intensive. Next, the decode phase consumes cached keys/values to generate tokens one at a time, making it memory bandwidth-bound. If this is all happening on a single GPU, it’s an inefficient use of resources, especially for long sequences.
llm-d improves this using disaggregation (separating workloads between specialized nodes or GPUs) and an inference gateway (kgateway) to evaluate the incoming prompt and intelligently route requests, dramatically improving both performance and cost efficiency. See Figure 1.
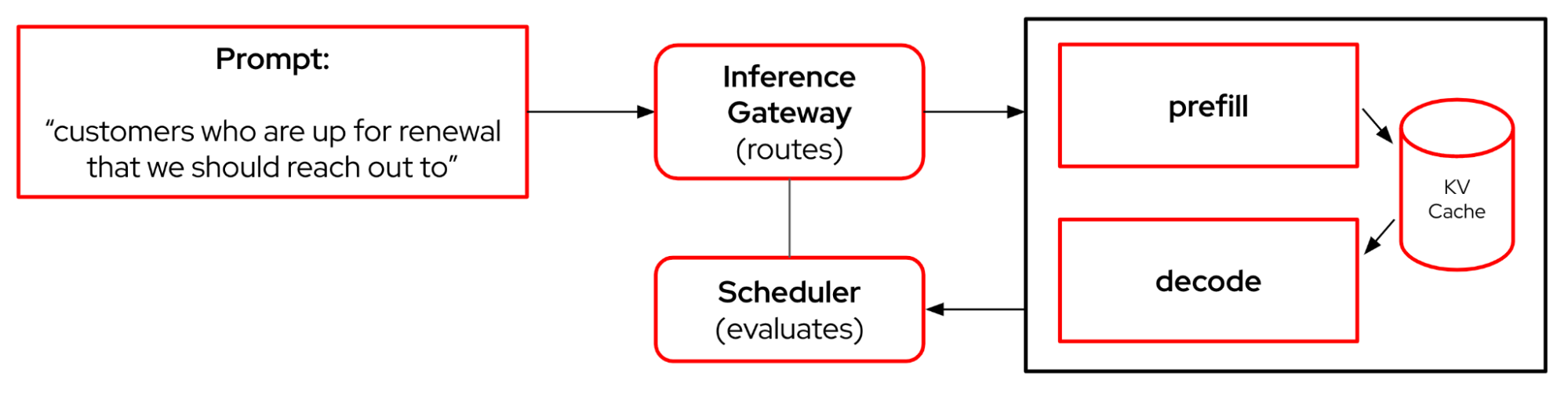
What are the main features of llm-d?
Before we look at how to deploy llm-d, let’s explore the features that make it unique.
Smart load balancing for faster responses
llm-d includes a special load scheduler that ensures each request is routed to the correct model server, built using Kubernetes’ Gateway API inference extension. Instead of using generic metrics, its inference scheduler uses smart rules based on real-time performance data—like system load, memory usage, and service level goals—to decide where to send each prompt. Teams can also customize how decisions are made, while benefiting from built-in features like flow control and latency balancing. Think of it as traffic control for LLM requests, but with AI-powered smarts.
Split-phase inference: Smarter use of compute
Instead of running everything on the same machine, llm-d splits the work:
- One set of servers handles understanding the prompt (prefill).
- Another set handles writing the response (decode). This helps use GPUs more efficiently—like having one group of chefs prep ingredients while another handles the cooking. It’s powered by vLLM and high-speed connections like NVIDIA Inference Xfer Library (NIXL) or InfiniBand.
Reusing past work with disaggregated caching
llm-d also helps models remember more efficiently by caching previously computed results (KV cache). It can store these results in two ways:
- Locally (on memory or disk) for low-cost, zero-maintenance savings.
- Across servers (using shared memory and storage) for faster reuse and better performance in larger systems. This makes it easier to handle long or repeating prompts without redoing the same calculations.
Getting started with llm-d
If we look at the examples in the llm-d-infra repository, the prefill/decode disaggregation example is targeted at larger models like Llama-70B, deployed on high-end GPUs (NVIDIA H200s). For this article, we’re going to focus on smaller models like Qwen3-0.6B on smaller GPUs (NVIDIA L40S). The example we’re going to deploy is Precise Prefix Cache Aware Routing. This is more suitable to the hardware we have available, and will allow us to demonstrate KV cache aware routing.
Prerequisites for llm-d
- Red Hat OpenShift Container Platform 4.17+.
- NVIDIA GPU Operator 25.3.
- Node Feature Discovery Operator 4.18.
- 2 NVIDIA L40S GPUs (e.g., AWS g6e.2xlarge instances).
- A Hugging Face token, with permissions to download your desired model.
- No service mesh or Istio installation, as Istio CRDs will conflict with the gateway.
- Cluster administrator privileges to install the llm-d cluster scoped resources.
Follow the steps in this repository for an example of how to install the prerequisites for llm-d on an OpenShift cluster running on AWS.
Installing llm-d
Now that you’ve installed the prerequisites, you’re ready to deploy llm-d.
Step 1: Clone the repository
Clone the llm-d-infra repository:
git clone https://github.com/llm-d-incubation/llm-d-infra.gitStep 2: Install dependencies
First, make sure you have the necessary CLI tools installed by running the setup script:
cd quickstart
./install-deps.shThis will install tools like Helmfile, Helm, and other utilities used throughout the deployment process.
Step 3: Deploy Gateway and the infrastructure via quick start
Use the quick start to deploy Gateway CRDs, Gateway provider, and the infra chart:
HF_TOKEN=$(HFTOKEN) ./llmd-infra-installer.sh --namespace llm-d -r infra-kv-events --gateway kgatewayNote that the release name infra-kv-events is important here, because it matches the prebuilt values files used in this example.
Once this script completes, you should see the kv-events-inference-gateway pod running in the llm-d namespace:
NAME READY STATUS RESTARTS AGE
infra-kv-events-inference-gateway-79766dfd99-g8z2v 1/1 Running 0 14s Step 4: Deploy the model and Gateway Interface Extension (GIE) charts
With the infrastructure live, use helmfile to apply the model service and GIE charts on top of it:
cd examples/precise-prefix-cache-aware
helmfile --selector managedBy=helmfile apply helmfile.yaml --skip-diff-on-installThis step deploys the actual model back end and associated services.
The ms-kv-events-llm-d-modelservice-decode pods are likely stuck in a pending state. In our example, this is because of taints applied to the GPU nodes. We need to add tolerations to the pods to allow scheduling on these nodes. We can do this with the following command.
oc patch deployment ms-kv-events-llm-d-modelservice-decode -p '{"spec":{"template":{"spec":{"tolerations":[{"key":"nvidia.com/gpu","operator":"Equal","value":"NVIDIA-L40S-PRIVATE","effect":"NoSchedule"}]}}}}'The pods should now be scheduled. After a few minutes they will be running, e.g.:
NAME READY STATUS RESTARTS AGE
gaie-kv-events-epp-c66494579-6lh9q 1/1 Running 0 2m2s
infra-kv-events-inference-gateway-79766dfd99-g8z2v 1/1 Running 0 4m2s
ms-kv-events-llm-d-modelservice-decode-75d599f954-hnrc4 2/2 Running 0 20s
ms-kv-events-llm-d-modelservice-decode-75d599f954-xgkw5 2/2 Running 0 29sYou’re now ready to send prompts through the inference gateway and test KV cache aware routing.
Testing KV cache aware routing
The easiest way to connect to the gateway is via port forwarding. Run the following command to enable it:
oc port-forward service/infra-kv-events-inference-gateway 8000:80Once this connection is established, from a separate terminal, run:
curl http://localhost:8000/v1/models You should see a response listing the models served, e.g.:
{
"data": [
{
"created": 1753453207,
"id": "Qwen/Qwen3-0.6B",
"max_model_len": 40960,
"object": "model",
"owned_by": "vllm",
"parent": null,
"permission": [
{
"allow_create_engine": false,
"allow_fine_tuning": false,
"allow_logprobs": true,
"allow_sampling": true,
"allow_search_indices": false,
"allow_view": true,
"created": 1753453207,
"group": null,
"id": "modelperm-28c695df952c46d1b6efac02e0edb62d",
"is_blocking": false,
"object": "model_permission",
"organization": "*"
}
],
"root": "Qwen/Qwen3-0.6B"
}
],
"object": "list"
}Now that we can connect to our llm-d deployment, we can test KV-cache aware routing. To do this, we’re going to use a larger message—one greater than 200 tokens, e.g.:
export LONG_TEXT_200_WORDS="Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."Now, let’s send this prompt to the llm-d gateway:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-0.6B",
"prompt": "'"$LONG_TEXT_200_WORDS"'",
"max_tokens": 50
}' | jqHow can we tell if this request is being routed based on the prefix? We can look at the logs from the gaie-kv-events-epp pod, specifically for the text Got pod scores.
oc logs deployment/gaie-kv-events-epp -n llm-d --follow | grep "Got pod scores"From our initial request, we should see something like:
Got pod scores {"x-request-id": "57dbc51d-8b2f-46a4-a88f-5a9214ee2277", "model": "Qwen/Qwen3-0.6B", "resolvedTargetModel": "Qwen/Qwen3-0.6B", "criticality": "Sheddable", "scores": null}This shows the prompt returned a null score, meaning it did not match a previously decoded prompt.
Now let’s try the same prompt again. We’re going to use the same curl command:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-0.6B",
"prompt": "'"$LONG_TEXT_200_WORDS"'",
"max_tokens": 50
}' | jqThis time we can see a prompt score with a pointer to the IP address of the preferred decode pod, based on the KV cache.
Got pod scores {"x-request-id": "585b72a7-71e4-4eaf-96bc-1642a74a9d8e", "model": "Qwen/Qwen3-0.6B", "resolvedTargetModel": "Qwen/Qwen3-0.6B", "criticality": "Sheddable", "scores": {"10.131.2.23":2}} If we look at the individual logs of the decode pods, we should see activity in the same pod when we send this large prompt.
To summarize, we’ve demonstrated how llm-d’s KV cache aware routing optimizes inference by intelligently directing requests to the most suitable decode pods and leveraging previously computed results. This approach significantly improves efficiency and reduces latency for repeated or similar prompts.
Community and contribution
llm-d is a collaborative effort with a strong emphasis on community-driven development. Launched with contributions from Red Hat, Google, IBM, NVIDIA, and AMD, it aims to foster a collaborative environment for defining and implementing best practices for LLM inference scaling. We encourage you to check out and engage with the project.
- Check out the llm-d project repository.
- Try out the llm-d quick start.
- Join the llm-d community on Slack to receive updates and chat with maintainers.
Wrapping up
With llm-d, there’s a significant step forward in making large-scale LLM inference practical and efficient in production environments, powered by the operationalizability of Kubernetes. By focusing on intelligent request routing, KV cache optimization, and prefill/decode disaggregation, it offers organizations the ability to unlock the full potential of their LLM applications in a cost-effective and performant manner.
Try out llm-d and join the growing community today!
The post Getting started with llm-d for distributed AI inference appeared first on Red Hat Developer.


