
A user reported a bug in pdf-parser: when dumping all filtered streams, an error would occur:
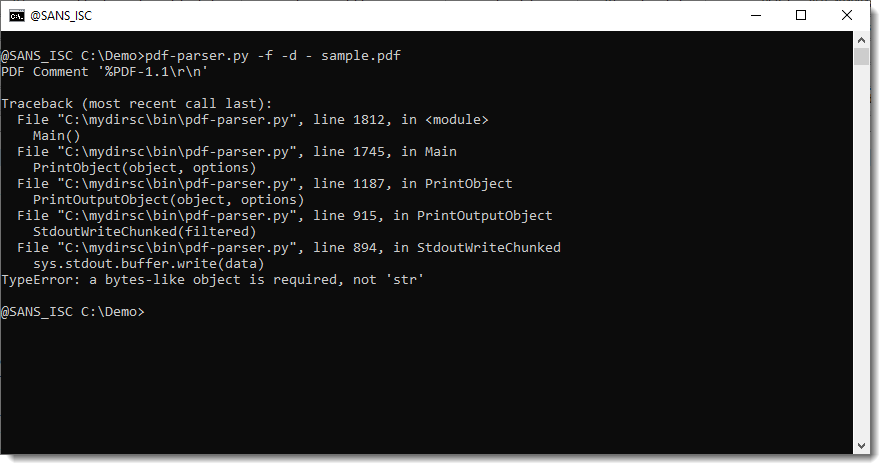
The reason for the error, is that not all streams have filters applied to them, and thus dumping a filtered stream that has no filter caused a bug.
I have fixed this:
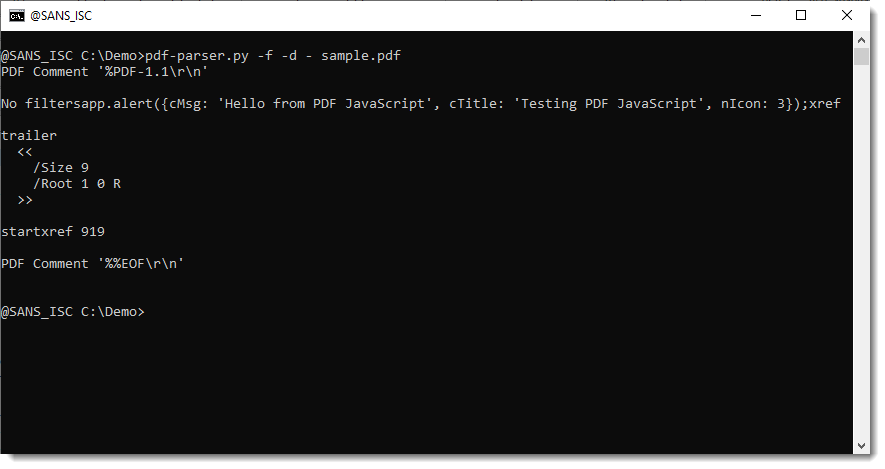
But I would like to point out that I think that a better way to look at the content of all the filtered streams, is to have pdf-parser produce JSON output and then display this with myjson-filter.py, like this:
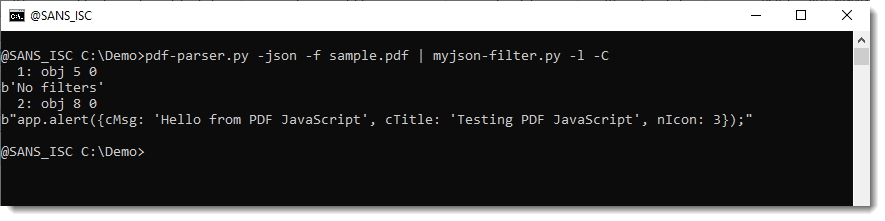
Now you see the content of the streams, and to which object they belong. And if there are no filters, you also see this: ‘No filters’.
Finally, the PDF comments that you saw in screenshot 2, are also gone: you only get streams.
Didier Stevens\
Senior handler\
blog.DidierStevens.com
A user reported a bug in pdf-parser: when dumping all filtered streams, an error would occur:The reason for the error, is that not all streams have filters applied to them, and thus dumping a filtered stream that has no filter caused a bug.
I have fixed this:But I would like to point out that I think that a better way to look at the content of all the filtered streams, is to have pdf-parser produce JSON output and then display this with myjson-filter.py, like this:Now you see the content of the streams, and to which object they belong.
And if there are no filters, you also see this: ‘No filters’.
Finally, the PDF comments that you saw in screenshot 2, are also gone: you only get streams.
Didier StevensSenior handlerblog.DidierStevens.com
A user reported a bug in pdf-parser: when dumping all filtered streams, an error would occur:

The reason for the error, is that not all streams have filters applied to them, and thus dumping a filtered stream that has no filter caused a bug.
I have fixed this:

But I would like to point out that I think that a better way to look at the content of all the filtered streams, is to have pdf-parser produce JSON output and then display this with myjson-filter.py, like this:

Now you see the content of the streams, and to which object they belong. And if there are no filters, you also see this: ‘No filters’.
Finally, the PDF comments that you saw in screenshot 2, are also gone: you only get streams.
Didier Stevens
Senior handler
blog.DidierStevens.com



